PPO – Continuous Control with Reinforcement Learning
This project explores Proximal Policy Optimization (PPO), a reinforcement learning algorithm known for its stability and strong empirical performance on continuous control tasks.
We implemented PPO from scratch and trained agents on three environments: Pendulum-v1, BipedalWalker-v3, and LunarLanderContinuous-v2.
🔍 What is PPO?
PPO is a policy-gradient method designed to improve stability in training by avoiding overly large policy updates.
The key idea is to clip the objective function, ensuring updates don’t move the policy too far from the old one:
Where:
- = probability ratio between new and old policy
- = advantage estimate (how much better an action is compared to baseline)
- = clipping threshold (commonly 0.1–0.3)
This clipping trick stabilizes learning, making PPO robust across a wide range of tasks without excessive hyperparameter tuning.
🌀 Environments and Results
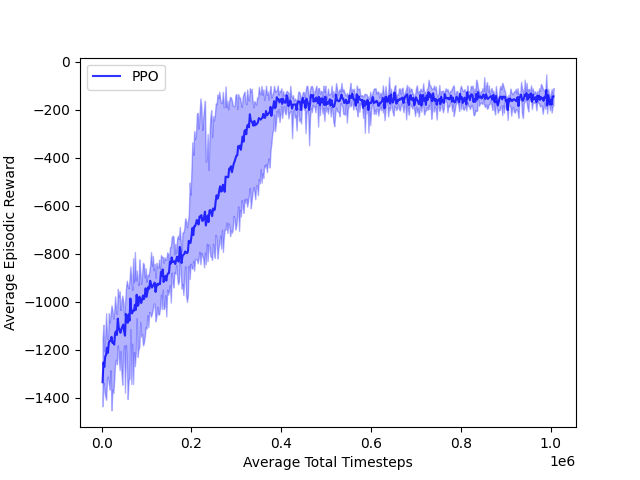
Pendulum-v1
Balance a pendulum upright by applying torque.
Goal: minimize swing and keep the pendulum near vertical.
Training Curve
Learned Behavior

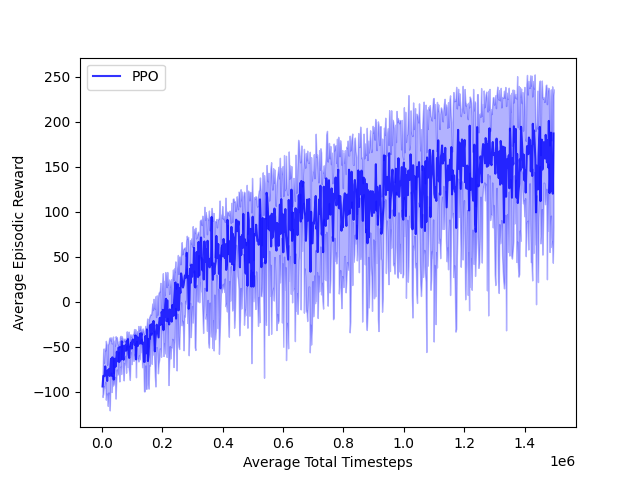
BipedalWalker-v3
Control a bipedal robot to walk across rough terrain.
Goal: maximize forward progress, avoid falling, and minimize energy use.
Training Curve
Learned Behavior

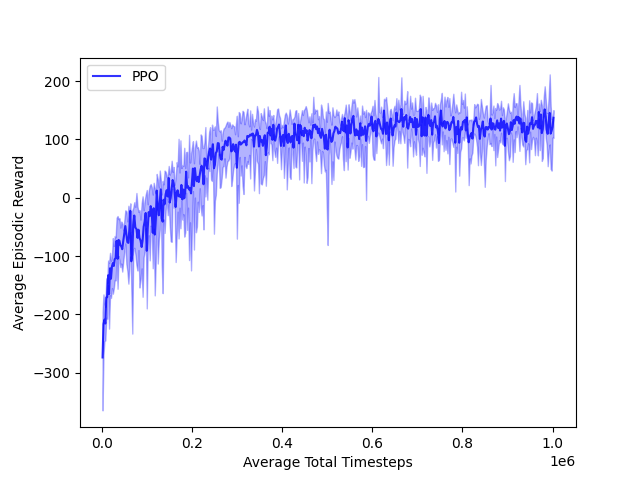
LunarLanderContinuous-v2
Land a lunar module on a target pad with continuous thrust control.
Goal: achieve a smooth landing with minimum fuel and without crashing.
Training Curve
Learned Behavior
🧠 Technical Insights
- Architecture: We used fully-connected networks with ReLU activations for both actor and critic.
- Advantage Estimation: Generalized Advantage Estimator (GAE) to reduce variance.
- Entropy Bonus: Encourages exploration by penalizing deterministic policies.
- Training Regime: Each update processes multiple epochs of minibatch data from trajectories.
Together, these elements make PPO sample-efficient and stable—even in noisy continuous-control environments.
📌 Conclusions
Across all three environments, the PPO agent demonstrated robust learning and converged to stable policies:
- Pendulum: Achieved stable upright control.
- BipedalWalker: Learned efficient walking gaits after thousands of episodes.
- LunarLander: Managed controlled landings with reduced crashes.
While results show the strength of PPO, further improvements could come from hyperparameter tuning, different network architectures, and longer training horizons.
📂 Resources
- Source Code on GitHub
- Environments: OpenAI Gym (
Pendulum-v1,BipedalWalker-v3,LunarLanderContinuous-v2)
PPO – Continuous Control with Reinforcement Learning
https://github.com/marcmonfort/ppo-continuous-control
Research Engineer