Deep Learning on HPC – MareNostrum5
Running deep learning experiments on a High-Performance Computing (HPC) system is a completely different experience compared to training locally on a laptop or even a single GPU workstation.
In this project I explored optimizer performance, learning rate effects, and scaling with multiple GPUs by running jobs on MareNostrum5, the flagship supercomputer of the Barcelona Supercomputing Center.
MareNostrum5 – Europe’s Tier-0 Supercomputer 🖥️
MareNostrum5 (MN5) is one of the most powerful machines in Europe, offering 314 PFLOPS of theoretical peak performance and ranking among the Top500 supercomputers.
Key specs (general partition):
- Compute nodes: Intel Sapphire Rapids + NVIDIA H100 GPUs
- Accelerated partition: 4× NVIDIA H100 Tensor Core GPUs per node
- High-speed interconnect: NVIDIA Quantum-2 InfiniBand (400 Gbit/s)
- Storage: GPFS-based parallel file system, optimized for massive I/O throughput

Unlike a personal machine, MN5 enables:
- Scaling across multiple GPUs and nodes.
- Running many experiments in parallel.
- Leveraging Slurm for resource allocation and job scheduling.
Submitting Jobs with Slurm ⚡
MareNostrum5 uses the Slurm workload manager to allocate resources. A typical job script looks like:
#!/bin/bash
#SBATCH --job-name=dl_mnist
#SBATCH --gres=gpu:2 # request 2 GPUs
#SBATCH --nodes=1
#SBATCH --time=00:20:00
#SBATCH --output=out_%j.log
module load tensorflow/2.15.0
srun python train.pyInstead of “just running the script,” you submit jobs to a queue. Slurm handles:
- Fair resource distribution across thousands of users.
- Efficient GPU/CPU scheduling.
- Automatic logging and error tracking.
This abstraction is both powerful and humbling—you think in terms of batches of experiments rather than single runs.
Experiments & Results
Optimizer Comparison
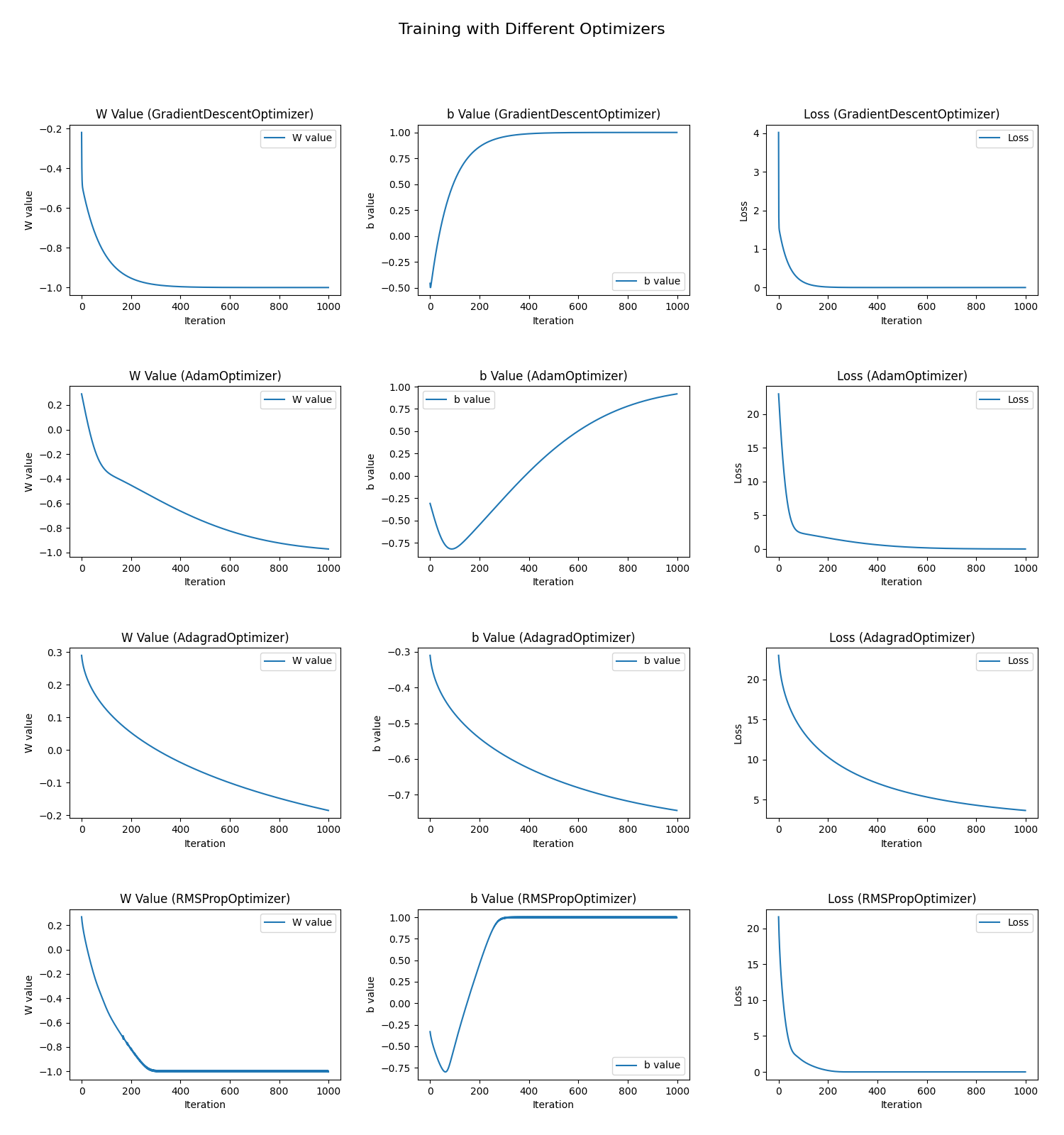
The first exercise focused on understanding how different optimization algorithms behave when training a simple linear regression model. The goal was to observe convergence speed, stability of parameters (weights and bias), and efficiency in minimizing loss.
- Adam & RMSProp: Delivered the fastest convergence and most stable trajectories. Their adaptive learning rate mechanisms helped avoid oscillations and sped up training.
- Gradient Descent: Worked reasonably well but required manual fine-tuning of the learning rate. Too high → divergence, too low → painfully slow progress.
- Adagrad: Started well, but its learning rate decayed too aggressively, leading to slow final convergence and suboptimal performance.
This experiment shows why modern optimizers like Adam and RMSProp are widely adopted—they combine speed with robustness.
Optimizers + Learning Rate Sweep
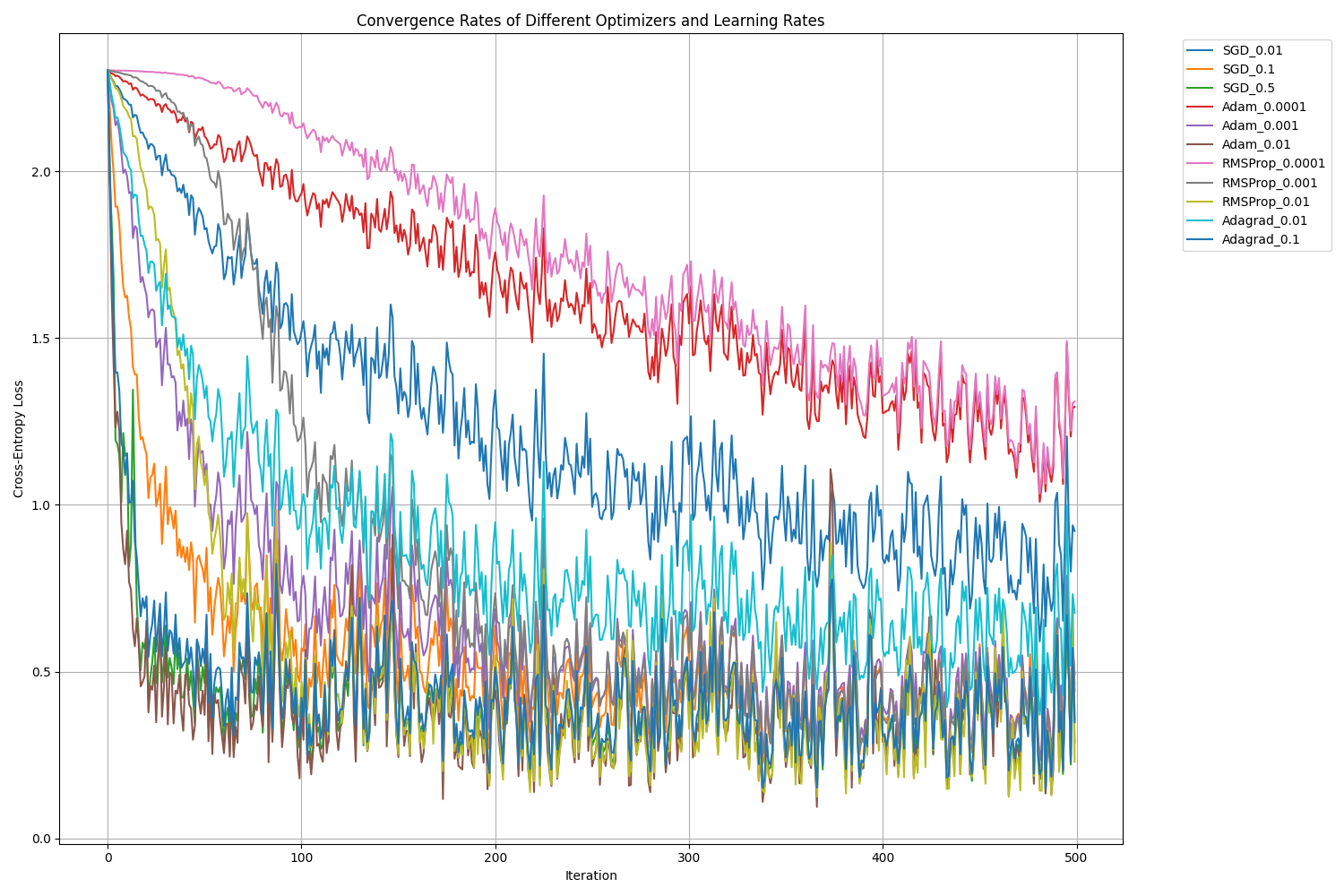
The second exercise extended the analysis by running a grid search over different optimizers and learning rates, then comparing convergence and final test accuracy on a classification task. This represents a realistic hyperparameter tuning workflow, which is exactly the kind of task HPC resources excel at.
Key insights:
- Adam (lr=0.01): Best overall, reaching 91.7% accuracy. Its adaptive mechanism consistently delivered top performance.
- RMSProp (lr=0.01): Nearly as good as Adam, showing its strength for non-stationary problems.
- SGD with lr=0.5: Surprisingly strong, proving that with the right learning rate, even “vanilla” optimizers can compete.
- Adagrad: The higher learning rate (0.1) compensated for its decaying schedule, giving better results than the smaller one.
This highlights that optimizer choice alone is not enough—learning rate tuning is critical. On HPC systems, running these sweeps in parallel shortens what could otherwise take days on a single machine.
MNIST Classification with Improvements
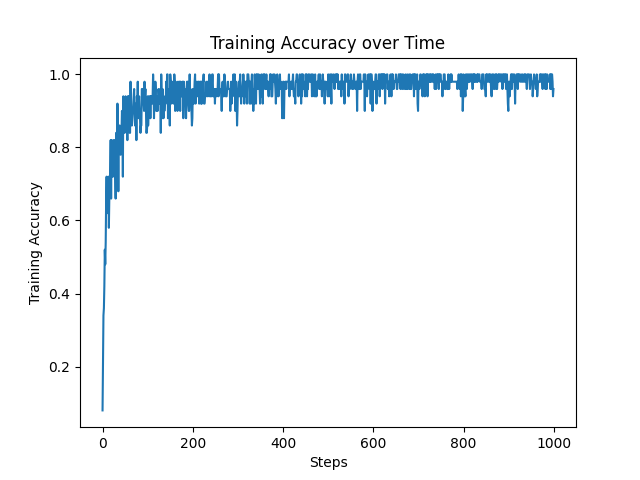
In the third exercise, the objective was to push accuracy further on the MNIST digit classification benchmark by introducing common deep learning best practices. Rather than focusing on optimizers, this experiment tested how training strategies and data handling can boost performance.
Techniques applied:
- Data augmentation (rotations, shifts, zooms) → improves generalization by teaching the model invariances.
- Stratified batches → ensures each mini-batch has a representative class distribution, stabilizing learning.
- Multi-epoch training → allows the network to fully exploit the augmented data.
These refinements resulted in a remarkable 99.4% test accuracy, close to state-of-the-art levels for MNIST. The training curve confirmed steady, near-perfect convergence.
Multi-GPU Scaling on MareNostrum5
Finally, the fourth exercise explored scaling training across multiple GPUs using tf.distribute.MirroredStrategy. This is a central question in HPC environments: does adding more GPUs always make training faster?
| GPUs | Training Time (s) |
|---|---|
| 1 | 2.229 |
| 2 | 1.609 |
| 3 | 1.589 |
| 4 | 1.594 |
Observations:
- Going from 1 → 2 GPUs yielded the biggest speedup (≈30% faster).
- Beyond 2 GPUs, the gains plateaued, as communication overhead between GPUs started to dominate.
- For this relatively small model, 2 GPUs was the sweet spot—more hardware did not translate to proportional benefits.
This reflects a common HPC reality: scaling is not infinite. The effectiveness of multi-GPU training depends on model size, data parallelism, and synchronization costs. Understanding these trade-offs is part of learning how to efficiently use HPC clusters like MareNostrum5.
Reflections – What HPC Changes
Compared to local runs:
- Scale & throughput: You can run tens of jobs in parallel.
- Efficiency: Large GPU clusters allow bigger batch sizes & faster sweeps.
- Discipline: Job queues force you to structure experiments (scripts, logs, checkpoints).
- Community: You share the machine with hundreds of other researchers—each job competes for time.
Working on HPC isn’t just “faster hardware.” It’s a different mindset: reproducibility, automation, and resource-aware design become essential.
Links
Deep Learning on HPC – MareNostrum5
https://github.com/marcmonfort/DL-HPC
Research Engineer