Cooperative Multi-Agent Deep RL with MATD3
This project explores cooperative multi-agent reinforcement learning (MARL) using the Multi-Agent Twin Delayed Deep Deterministic Policy Gradient (MATD3) algorithm.
The goal was to compare two learning strategies:
- Independent Learners – each agent learns with only its local observations/rewards.
- Fully Observable Critic – agents share a central critic with access to the global state.
The experiments were conducted in the Simple Spread and Simple Speaker Listener environments from the PettingZoo MPE suite.

Simulation Environments
Simple Spread
- 3 agents, 3 landmarks
- Agents must spread to cover all landmarks while avoiding collisions.
- Reward = global coverage (distance to landmarks) – collision penalties.
Simple Speaker Listener
- 2 agents: one speaker, one listener
- The speaker sees the goal landmark but cannot move.
- The listener moves but does not see the goal—it relies on the speaker’s communication.
MATD3 Algorithm
MATD3 extends TD3 to multi-agent settings with:
- Actor-Critic architecture (separate networks for policy and value estimation).
- Double Critics to mitigate Q-value overestimation.
- Target Networks + Delayed Policy Updates for training stability.
- Action Noise for better exploration.
MATD3 Pseudocode

Actor-Critic Diagram
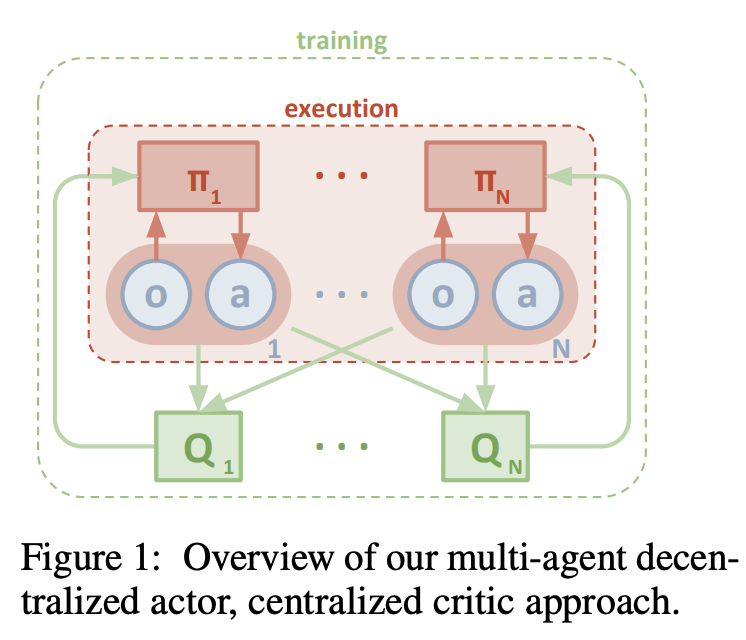
Independent Learners vs Fully Observable Critic
-
Independent Learners
Each agent has its own critic, based only on its local observations.- Pros: scalable, decentralized.
- Cons: less coordination.
-
Fully Observable Critic
A centralized critic sees the entire environment state and all agent actions.- Pros: better coordination and performance.
- Cons: slower training, heavier computation.
Experimental Setup
- Framework: AgileRL
- Training episodes: 6000
- Optimization: Evolutionary Hyperparameter Search
- Metrics: episodic reward, learning stability, task completion
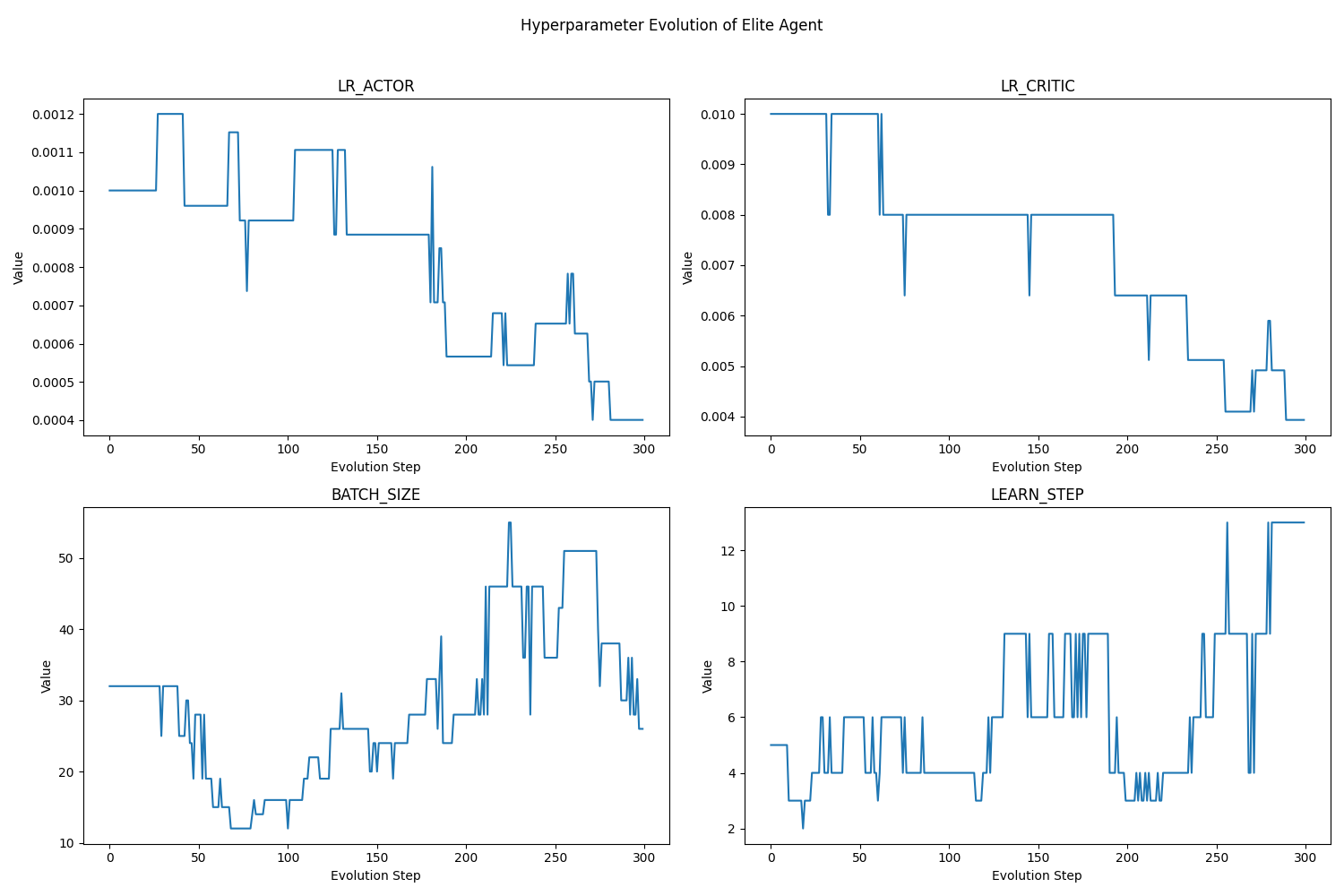
Results
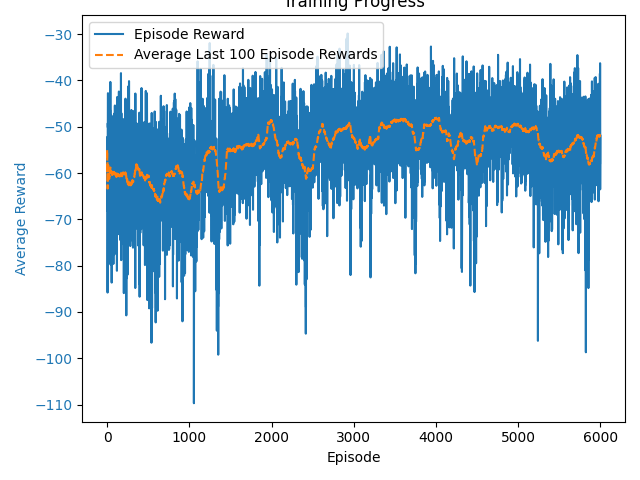
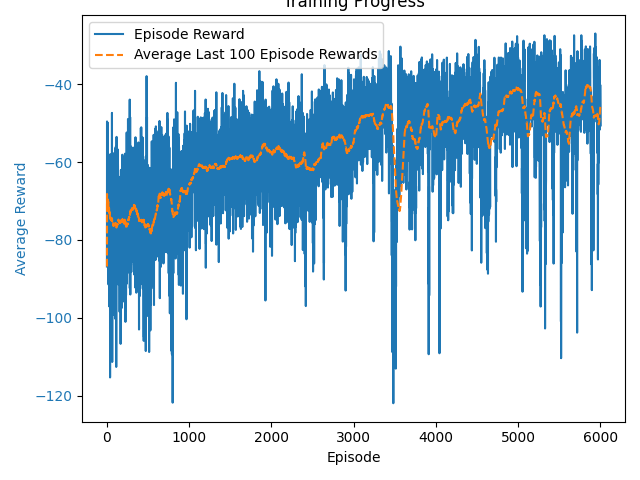
Simple Spread
Independent Learners – Training Curve
Independent Learners – Learned Behavior

Fully Observable Critic – Training Curve
Fully Observable Critic – Learned Behavior

Simple Speaker Listener
Independent Learners – Training Curve
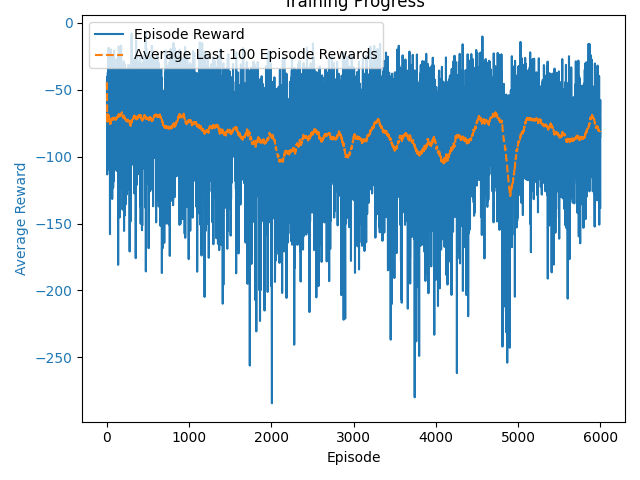
Independent Learners – Learned Behavior

Fully Observable Critic – Training Curve
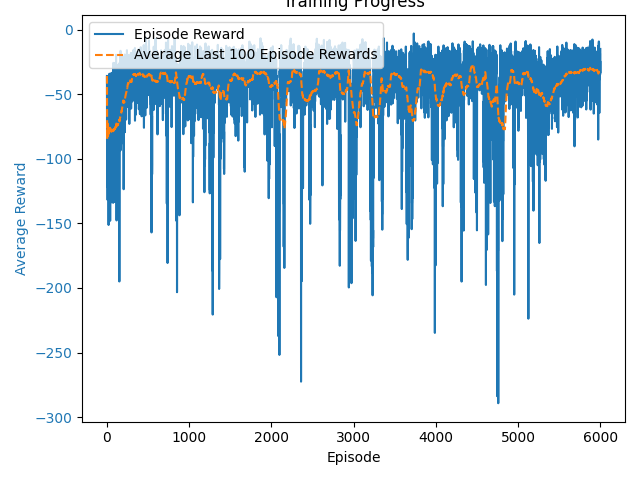
Fully Observable Critic – Learned Behavior

Final Rewards
| Environment | Independent Learners | Fully Observable Critic |
|---|---|---|
| Simple Spread | -48.83 | -41.05 |
| Simple Speaker Listener | -53.12 | -35.55 |
Conclusions
- The Fully Observable Critic consistently outperformed Independent Learners in both environments, but required longer training time.
- Independent Learners trained faster, but showed higher variance and weaker coordination.
This project highlights the trade-off between decentralized efficiency and centralized performance in cooperative MARL.
Repository
👉 Source code and experiments: SOAS-MADRL on GitHub
Cooperative Multi-Agent Deep RL with MATD3
https://github.com/marcmonfort/SOAS-MADRL
Research Engineer